これらの混乱したデータモデルに接触したとき、本当に混乱しました。アーキテクチャを設計する際も混乱していて、データモデルに基づいて対応するパッケージ名をどう取得するか分かりませんでした。私はネット上のさまざまな資料を調べましたが、誰も分かりやすく説明していませんでした。それで、自分の経験に基づいて整理しました。
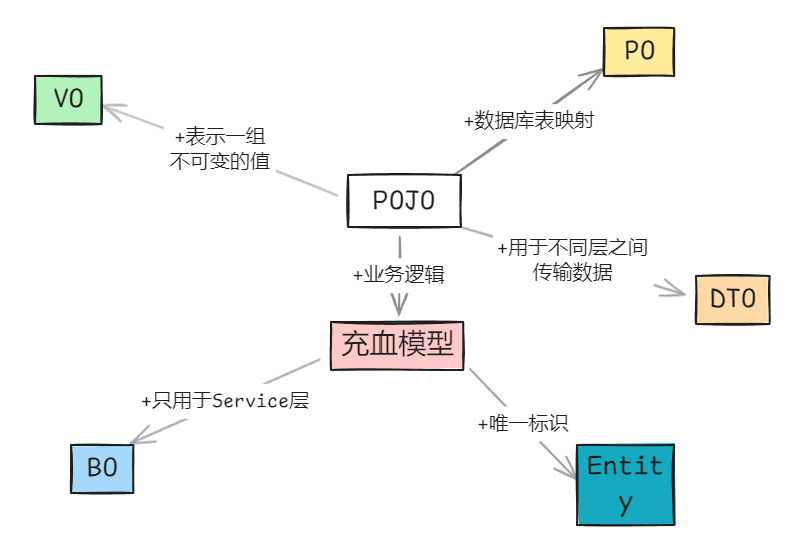
POJO【plain old java object】普通の Java オブジェクトで、他のデータモデルの基礎として使用できます。VO【value object】 :値オブジェクトは不変のオブジェクトで、唯一の ID 識別子を持たない、一組の値を表すために使用されます【つまり、2 つの値オブジェクトの属性が同じであれば、それらは等しいと見なされます】- 簡単なビジネスロジック操作を含むことができます。
- VO では通常、値に基づいて比較できるように equals と hashCode メソッドをオーバーライドします。
PO / エンティティ【Entity】 :エンティティは唯一の ID 識別子を持つ必要があります。つまり、2 つのエンティティの属性値が同じであっても、それらは等しくありません;PO はデータベーステーブルにマッピングされた Java オブジェクトです【したがって、PO とエンティティは同じ概念と見なすことができます】DTO【data transfer object】:DTO は異なる層間でデータを転送するために使用されます。- いかなるビジネスロジックも含まれていません。
充血モデル:充血モデル = PO + ビジネスロジック、もしある PO にビジネスロジックが含まれているなら、それは充血モデルですBO【Business object】:ビジネスオブジェクトはビジネスロジックを含みます。- サービス層でのみ使用されます。